I finally finished my Master’s Thesis in the Computer Vision chair at TUM. In the course of this thesis, I analyzed existing deep learning approaches to predict future frames in videos. Based on these findings and other modern deep learning practices, such as batch normalization, scheduled sampling to improve recurrent network training or ConvLSTMs, we were able to reach or event outperform state-of-the-art performance in future frame generation.
So far, many people asked me about the practical application of frame prediction. Unfortunately, it won’t tell us the end of any cliff-hanger movie such as Inception, but the main purpose of such a system is not to generate a perfect forecast of the long-term continuation of any movie clip. This completely impossible in my opinion, since there is not always a wrong or right in many situations. A neural network cannot be able to predict every decision made by all objects inside the scene. Furthermore, the pose of the camera or the environment could change unexpectedly. More interestingly, the trained model has to be able to distinguish foreground and background, as well as encode the content and dynamics of the frame sequence. In this thesis, we use this learned representations to predict the possible future frame sequence, using a completely unsupervised learning process. Parts of this trained neural network could be reused in any supervised learning task, such as action recognition in videos. Also, a similar model architecture could be used to train a neural network that is able to generate high speed videos using frame interpolation, or in context of video compression.
But let’s get back to the application example that was used within the thesis: future frame prediction in videos. To assess the model, we used three different datasets with increasing complexity. First, we used MovingMNIST using two digits (top). Surprisingly, the model also delivered good results when we performed an out-of-domain test using one or three digits (bottom). The ground truth animation on the left is shown in comparison to the multi-step frame prediction to the right.
 MovingMNIST predicted on proposed Conv2D LSTM model using three digits
MovingMNIST predicted on proposed Conv2D LSTM model using three digits
 MovingMNIST predicted on proposed Conv2D LSTM model using three digits
MovingMNIST predicted on proposed Conv2D LSTM model using three digits
In a second experiment, we used video game recording of MsPacman. As it can be seen in the prediction example below, our trained 2-layer ConvLSTM Encoder-Predictor model is able to capture several dynamics of the game, such as the movement of Pacman and the ghosts, the blinking of the big dot in the top-right corner, as well as es fact that Pacman is eating the dots within the maze.
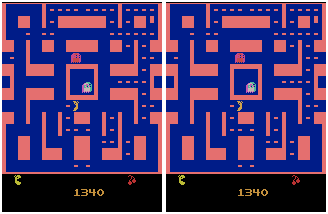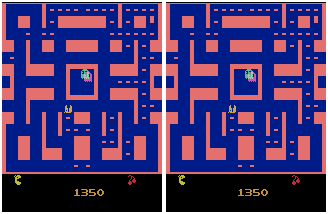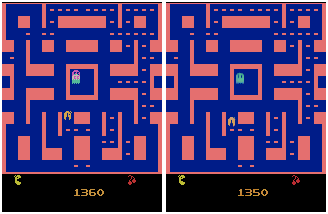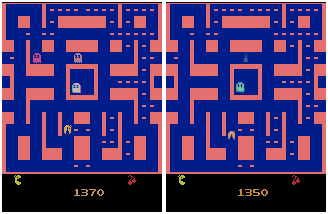 MsPacman predicted on proposed Conv2D LSTM model
MsPacman predicted on proposed Conv2D LSTM model
In our last experiment, we trained our model on the UCF-101 training set. This is a much harder problem, since the environment comes with unlimited possibilities, the camera could exhibits movement and rotation, and so on. Like many other solutions, we can notice a blur-effect in the generated future frames, even that we take advantage of perceptual motivated loss terms, such as SSIM or GDL. However, some results look satisfactory nonetheless. As an example, the zooming of the camera is captured and correctly continued in the soccer example below.
 UCF-101 predicted on proposed Conv2D LSTM model
UCF-101 predicted on proposed Conv2D LSTM model
Of course, there is much more to tell. But the main intention of this post is to provide a rough idea about what has been done, as well to show some prediction examples of my trained recurrent decoder-encoder network. In case would like to know more about it, just have a look at my written Master’s Thesis or write a comment to this post.