Frame Prediction – Beyond a Video with Deep Learning
This research project has been developed in Python using TensorFlow, NumPy and my high-level framework TensorLight. The code is available as open source in my GitHub/imseq repository. Furthermore, in case you would like to read my Master’s thesis in detail, then please feel free to check it out. Otherwise, the following sections should give you a brief summary of the most important bits.
Motivation
In recent years, the field of deep learning achieved considerable success and according to its underlying philosophy: “if we have a reasonable end-to-end model and sufficient data for training it, we are close to solving the problem.”1. But while there has been a lot of studies and practical applications of object recognition on static images or speech recognition, the application of these concepts on video data are just about to make their first steps in research.
Early deep learning approaches dealing with video data or simple image sequences address problems like human action recognition or video classification. Another example is optical flow prediction in order to detect the visual flow from one frame to the next. Most of these approaches require lots of labeled data to be able to train a network. The effortful labeling process and thus the resulting low availability of such data might be the main reason why this topic has not been covered that well so far. On the contrary, online services like YouTube provide a seemingly endless, but unlabeled source of videos to learn from.
Problem Statement
Throughout this thesis, it is investigated whether deep learning techniques can be successfully applied on videos to learn a meaningful representation in a completely unsupervised fashion. In detail, it is examined if such a representation is suited to continue a video even after it has finished. Hence, to learn a notion of the spatial and temporal evolution within a sequence of images as well as to get an idea of motion and dynamics of a scene. Such a high-level understanding would be helpful for autonomous intelligent agents that have to act and therefore understand our environment including its physical and temporal constrains2. Other application areas might be for instance video compression3, visual systems for autonomous cars or as a replacement for optical flow in causal video segmentation4. Aside from that, other supervised learning tasks like human action recognition could benefit from such a pre-trained network in order to improve the overall performance or to reduce the training time. Needless to say, other forms of transfer learning are easily conceivable as well.
Network Architecture
The network architecture used in the thesis is based on the recurrent encoder-decoder architecture5 6. A first encoder RNN sequentially processes the input data and therefore preserves the temporal correlations of the data. The second decoder RNN is then initialized with the hidden state of the first recurrent network and is then able to generate the future predictions one after another by unrolling the network.
 Basic structure of a conditional recurrent autoencoder. The inputs (green) are processed by the encoder RNN to learn the representation of the data in sequence. Then, the decoder RNN takes over to infer the reconstructions (blue) of the inputs in reverse order.
Basic structure of a conditional recurrent autoencoder. The inputs (green) are processed by the encoder RNN to learn the representation of the data in sequence. Then, the decoder RNN takes over to infer the reconstructions (blue) of the inputs in reverse order.
In order to preserve the spatial structure of the data within the recurrent network cells, convolutional LSTM cells1 are used. Technically, all internal matrix multiplications are exchanged with convolution operations. As a consequence, the data in feature space that flows through the ConvLSTM cells has a 3D shape instead of being just a 1D vector.
 The simplified structure of the batch-normalized ConvLSTM cell including peephole connections. The inputs and previous hidden states are convolved to produce 3D tensors that flow through each cell. Changes to standard FC-LSTM are highlighted in red.
The simplified structure of the batch-normalized ConvLSTM cell including peephole connections. The inputs and previous hidden states are convolved to produce 3D tensors that flow through each cell. Changes to standard FC-LSTM are highlighted in red.
The ConvLSTM implementation shown above further takes advantage of peephole connections and internal batch normalizations7. The use of the latter modifications did not show any improvements, but had a negative effect on the overall training performance; hence these have not been used in the final evaluation.
To improve the training process of the decoder RNN, a recurrent training strategy called scheduled sampling8 is used. By using this strategy, the trained network always ended up in a better prediction performance.
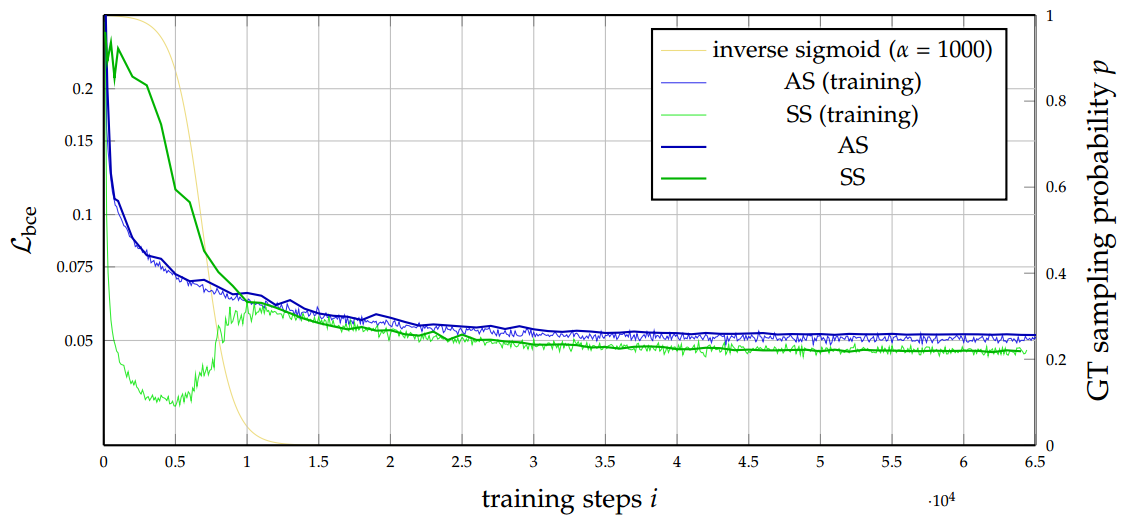 Influences of scheduled sampling regarding the training and validation error in context of recurrent networks and future frames prediction on Moving MNIST.
Influences of scheduled sampling regarding the training and validation error in context of recurrent networks and future frames prediction on Moving MNIST.
The overall network architecture consists of 5 major components, namely spatial encoder, spatio-temporal encoder, spatio-temporal decoder, spatial decoder and perceptual motivated loss layer. The network was trained end-to-end.
 The ConvLSTM Encoder-Predictor Model. Weights of the convolutional encoder (green) and decoder (blue) are shared layer-wise across the whole sequence. Spatial encodings of the ground truth frames, scheduled sampling components (yellow) and the loss layer (red) are only used while training.
The ConvLSTM Encoder-Predictor Model. Weights of the convolutional encoder (green) and decoder (blue) are shared layer-wise across the whole sequence. Spatial encodings of the ground truth frames, scheduled sampling components (yellow) and the loss layer (red) are only used while training.
In case you would like to know more about the technical implementation details and the recurrent encoder-predictor model, please have a look at my linked Master’s thesis at the top of this page.
Evaluation of Results
The network model has been assessed using tree different datasets with increasing complexity. In all experiments, the network was trained for only 100,000 steps using a 2-layer ConvLSTM, ADAM optimizer9 in its default settings but η=0.0005, scheduled sampling and batch normalization in each convolutional layer of the spatial encoder and decoder on a single Nvidia GTX Titan X GPU. All shown samples are generated using the test set.
Moving MNIST dataset
The Moving MNIST dataset has been used in the first experiment to explore the hyperparameters of the model. In this dataset, two handwritten digits bounce inside a black colored square at size 64 × 64. Even that this dataset looks very simple, the network has to deal with a high degree of occlusion.
 Frame prediction results of Moving MNIST with 2 digits using the proposed model (right) compared to the ground truth (left).
Frame prediction results of Moving MNIST with 2 digits using the proposed model (right) compared to the ground truth (left).
Even when the model instance is trained on samples with two digits only, it is also able to deal with samples having one or three digits as well, due to the fully-convolutional approach. In contrary, other existing approaches are dealing with a hallucination or merging effect.
 Frame prediction results of Moving MNIST with 3 digits using the proposed model (right) compared to the ground truth (left).
Frame prediction results of Moving MNIST with 3 digits using the proposed model (right) compared to the ground truth (left).
MsPacman dataset
In a second experiment, we use the MsPacman dataset that contains recordings of the classic video game. To successfully predict the future frames in this dataset, the network requires to encode the content and the dynamics happening in the random crop of size 32 × 32. Additionally, the neural network has to understand the game rules and environment on a primitive level. Due to the fully-convolutional approach, it is able to do inference on the full-sized frame as well.
 Frame prediction results of MsPacman using the proposed model (right) compared to the ground truth (left).
Frame prediction results of MsPacman using the proposed model (right) compared to the ground truth (left).
UCF-101 dataset
The last experiment uses the UCF-101 dataset without its labels for human action recognition. This is the most complex task, since the image space is not limited to specific colors, as well as the endless possibilities of e.g. motion or camera changes. In many generated examples, the effect of slowly disappearing foreground objects of fast moving objects can be observed. One possible reason for this might be that the kernel size of the ConvLSTM cells, which defines the maximum possible motion between two frames, has been chosen to be too low.
 Frame prediction results of UCF-101 using the proposed model (right) compared to the ground truth (left).
Frame prediction results of UCF-101 using the proposed model (right) compared to the ground truth (left).
References
Shi et al., 2015 – Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting ↩ ↩2
Srivastava et al., 2015 – Unsupervised Learning of Video Representations using LSTMs ↩
Ascenso et al., 2005 – Improving Frame Interplation with Spatial Motion Smoothing for Pixel Domain Distributed Video Coding ↩
Couprie et atl., 2013 – Causal graph-based video segmentation ↩
Cho et al., 2014 – Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation ↩
Sutskever et al., 2014 – Sequence to Sequence Learning with Neural Networks ↩
Cooijmans et al., 2016 – Recurrent Batch Normalization ↩
Bengio et al., 2015 – Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks ↩
Kingma et al., 2014 – Adam: A Method for Stochastic Optimization ↩