In the last post, I wrote about how to setup an eGPU on Ubuntu to get started with TensorFlow. I shortly mentioned that a eGPU is definitely worth it for Machine Learning, but I did not tell any numbers. This article tries to catch up on that. There are a gazillion benchmarks already out there about GPU gaming performance. A handful of them also include eGPU benchmarks, such as this example by egpu.io. One important thing that that these eGPU benchmarks show is that the use of an external display isfrom benefit, because otherwise the Thunderbolt 3 port becomes a bigger bottleneck. This is due to the fact that each rendered frame has be sent back to the internal display, which consumes valuable bandwidth of the 40 Gbps Thunderbolt 3 connection. However, there is no alternative for using an eGPU for Machine Learning, because the computed gradients have to be sent back to the CPU.
Talking about Machine Learning, there are a few articles our official benchmarks about TensorFlow performance available, but either these are about desktop performance, or about multiple Tesla GPUs for business. With this post, I want to put a focus on the eGPU performance, how it compares to the pure CPU performance of the notebook. Furthermore, I added some more results to have a better comparability. In detail, I added the performance of my previous and still beloved ThinkPad X220 from 2011, as well as the CPU and GPU offers from FloydHub. Together with my new ThinkPad X1 Carbon 6th Generation notebook, I run these test configurations on 3 different data-sets and models, using the default settings provided by tensorflow/models, namely CIFAR10 and MNIST using a CNN, and PTB using an LSTM.
Test setup
The used hardware specs of the benchmarks is as follows:
- X220 CPU: i5-2520M (2 cores), 8 GB RAM, 250 GB Samsung Evo 850 SSD
- Floyd CPU: Intel Xeon (2 cores), 8 GB RAM, 100 GB SSD
- Using free Beginner pricing
- Floyd GPU: Nvidia Tesla K80 12 GB VRAM, 61 GB RAM, 100 GB SSD
- The Tesla K80 is actually a dual-GPU with 24 GB VRAM total
- Using free Beginner pricing and 10h free GPU access
- X1 CPU: i7-8550U (4 cores), 16GB RAM, 512GB NVMe SSD
- X1 eGPU: Nvidia GTX 1070Ti 8GB VRAM, 16GB RAM, 512GB NVMe SSD
- Via Sonnet Breakaway Box 350W and Thunderbolt 3 with 40Gbps
And the software setup is the following:
- Ubuntu 17.10
- Nvidia driver 387.34
- Python 3.6.3
- TensorFlow r1.5 (pip package)
Benchmark
Let’s get started with the first benchmarks. In each benchmark, I ran either the whole script with default settings, or the model for some minutes and took the average examples/seconds of the last 10 outputs to get a rough estimate of the performance.
CIFAR-10
This script can be found on GitHub and is described it detail on the TensorFlow website. It is a common benchmark in machine learning for image recognition. It uses a simple convolutional neural network architecture described in this TensorFlow tutorial.
We did not change any of the default values. Consequently, we used a batch size of 128, while each image has a size of 24x24 pixels. In contrast, the original CIFAR-10 benchmark uses 32x32 pixel images.
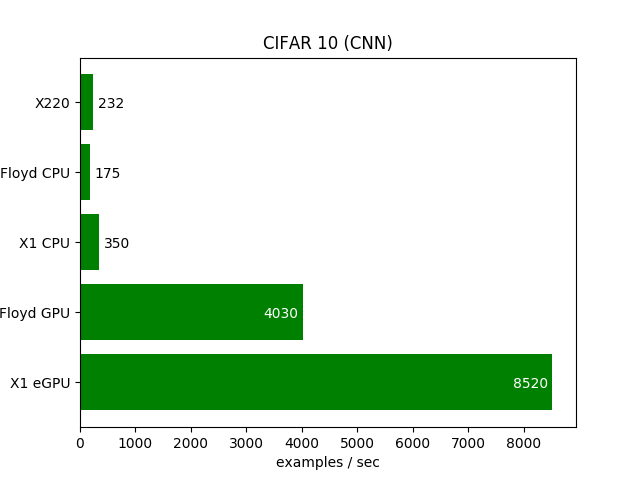 Benchmarks using a CNN on the CIFAR-10 dataset
Benchmarks using a CNN on the CIFAR-10 dataset
While executing this model on the X1 eGPU, only about 601MB of the VRAM are occupied, while the GPU is utilized by about 85%. One thing that is to note for the X1 CPU setup it starts with up to 850 examples/sec for about 50 batches, which then quickly drops down to about 350 examples/sec on average. I guess this might be due to throttling of the CPU, which is a common “problem” in ULV CPUs, which are not built for continuous workload, especially in a super thin notebook like the X1 Carbon. The Floyd CPU performance is underwhelming. Also the Floyd GPU performance of the Tesla GPU, which is less then half of the GTX 1070Ti used in X1 eGPU.
MNIST
The script for this benchmark can be found on GitHub and the detailed description of the model on the TensorFlow website. This model uses a simple 2-layer CNN for image classification. To be honest, I actually wanted to use a fully-connected model here instead, but no standard model was provided by TensorFlow. Also, I did not want to come up with my own model, because I hope using standard models makes it easier to compare these number with results from others. Again, we did not change the default hyperparams. Consequently, we are using images of size 28x28 pixel and a batch-size of 64 for 10 epochs, with a validation of 5000 samples every 100 training steps.
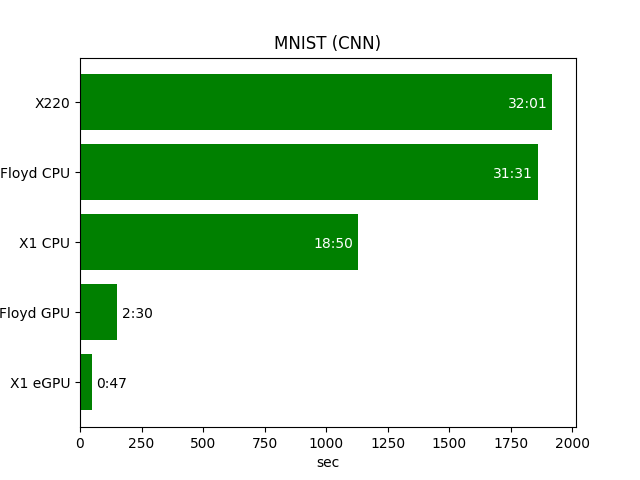 Benchmarks using a CNN on the MNIST dataset
Benchmarks using a CNN on the MNIST dataset
During training, the 465 MB VRAM of the eGPU was used, while it was utilized by about 81%. Since this benchmark is quite small, I timed the full training using the time python convolutional.py. Comparing my old X220 CPU which I still used about a month ago with my new X1 eGPU setup, instead of waiting for half an hour, it does not even take a minute anymore. That’s a huge difference!
PTB
This script can be found on GitHub and is based on this whitepaper. It uses a 2-layer LSTM model with 200 hiden units on a challenging task of language modeling. The default small config is used, which uses a batch-size of 20.
Benchmarks using an LSTM on the PTB dataset
The relative performance is more or less similar to both benchmarks before. Honestly speaking, I actually thought the performance speedup of a GPU on a recurrent model is lower compared to a CPU than on a convolutional model. But it looks like I was wrong.
When you compare my results to the ones from this Medium article, it looks like the Thunderbolt 3 bottleneck is almost negligible when the eGPU is used for machine learning.